Next: Solving the Least-Squares Problem
Up: Approximate Policy Iteration
Previous: Approximate Policy Iteration
The algorithm using Monte Carlo method
- Since we have too many states, lets take only subset of the states -
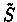 .
.
-
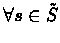 ,
there are M(s) runs :
c( s,1 ) ... c( s,M(s)).
,
there are M(s) runs :
c( s,1 ) ... c( s,M(s)).
- We look for r, which minimizes,
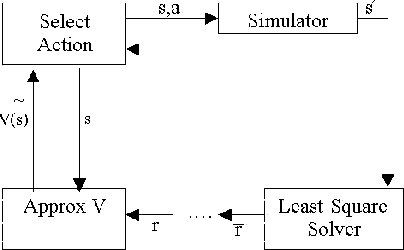
Figure:
Diagram for a mechanism that produces Approximate Policy Iteration
 |
Yishay Mansour
2000-01-11