


Next: The algorithm using Monte
Up: Large State Space
Previous: Example showing that tied
Approximate Policy Iteration
The general structure is the same as in the Policy Iteration, except the following differences:
- We will not use
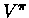 ,
instead we use
,
instead we use
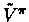 (or
(or
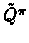 ), which is only an approximation of .
The reasons of using approximations are the architecture that may not be strong enough and the noise caused by the simulations.
), which is only an approximation of .
The reasons of using approximations are the architecture that may not be strong enough and the noise caused by the simulations.
- Let
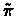 be the greedy policy of
.
We might take
be the greedy policy of
.
We might take  ,
which is close to
.
,
which is close to
.
Those two differences are a source for an error.
Figure:
Regular Policy Iteration
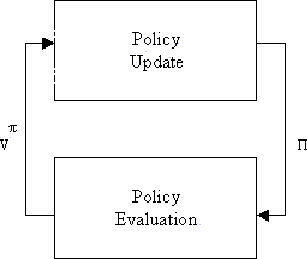 |
Figure:
Approximate Policy Iteration
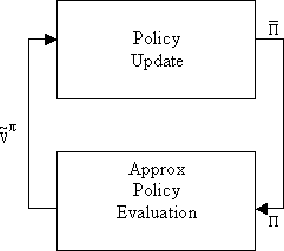 |
Yishay Mansour
2000-01-11