


Next: Profile Alignment
Up: Hidden Markov Models
Previous: Forward and Backward Probabilities
Parameter Estimation for HMMs
In examples 6.3 and
6.4 we constructed hidden Markov models
knowing the transition and emission probabilities for the problems
we had to solve. In real life, this may not be the case. We may be
given n strings
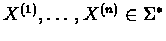 of
length
of
length
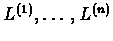 ,
respectively, which were all
generated from the HMM
,
respectively, which were all
generated from the HMM
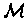
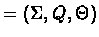 .
The
values of the probabilities in
.
The
values of the probabilities in 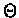 are, however, unknown
a-priori.
are, however, unknown
a-priori.
In order to construct the HMM that will best characterize
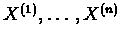 ,
we will have to assign values to
that will maximize the probabilities of our strings
according to the model. Since all strings are assumed to be
generated independently, we can write:
,
we will have to assign values to
that will maximize the probabilities of our strings
according to the model. Since all strings are assumed to be
generated independently, we can write:
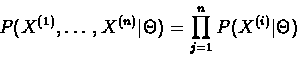 |
(6.29) |
Using the logarithmic score, our goal is to find
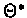 such
that
such
that
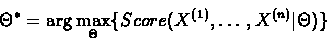 |
(6.30) |
where:
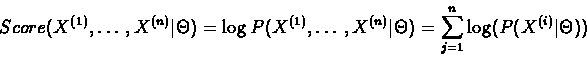 |
(6.31) |
The strings
are usually called the
training sequences.
Case 1: Assuming we know the state sequences
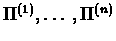 corresponding to
,
respectively. We can scan these sequences and compute:
corresponding to
,
respectively. We can scan these sequences and compute:
- Akl - the number of transitions from the state k to l.
- Ek(b) - the number of times that an emission of the symbol
b occurred in state k.
The maximum likelihood estimators will be:
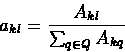 |
(6.32) |
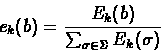 |
(6.33) |
To avoid zero probabilities, when working with a small amount of
samples, it is recommended to work with A'kl and E'k(b),
where:
| A'kl |
= |
Akl + rkl |
(6.34) |
| E'k(b) |
= |
Ek(b) + rk(b) |
(6.35) |
Usually the Laplace correction, where all rkl and
rk(b) values equal 1, is applied, having an intuitive
interpretation of a-priori assumed uniform distribution. However,
it may be beneficial in some cases to use other values for the
correction (e.g. when having some prior information about the
transition or emission probabilities).
Case 2: Usually, the state sequences
are not known. In this case, the problem of finding the
optimal set of parameters
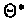 is known to be
NP-complete. The Baum-Welch algorithm [2], which
is a special case of the EM technique (Expectation and
Maximization), can be used for heuristically finding a solution
to the problem.
is known to be
NP-complete. The Baum-Welch algorithm [2], which
is a special case of the EM technique (Expectation and
Maximization), can be used for heuristically finding a solution
to the problem.
- 1.
- Initialization: Assign values to .
- 2.
- Expectation:
- (a)
- Compute the expected number of state transitions from
state k to state l. Using the same arguments we used for
computing
 (see 6.27), we get:
(see 6.27), we get:
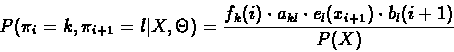 |
(6.36) |
Hence, we can denote the expectancy:
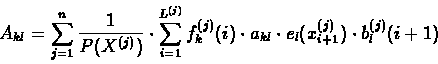 |
(6.37) |
- (b)
- Compute the expected number of emissions of the symbol b that
occurred at the state k (using the value of
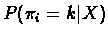 as
calculated in 6.28):
as
calculated in 6.28):
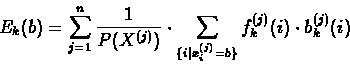 |
(6.38) |
- 3.
- Maximization: Re-compute the new values for
from
Akl and Ek(b), as explained above (in case 1).
- 4.
- Repeat steps 2 and 3 until the improvement of
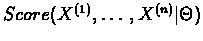 is less then a given
parameter
is less then a given
parameter 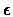 .
.
Since the values of the target function
are monotonically increasing and as logarithms
of probabilities are certainly bounded by 0, the algorithm is
guaranteed to converge. It is important to notice that the
convergence is of the target function and not in the
space: the values of
may change drastically even for
almost equal values of the target function, which may imply that
the obtained solution is not stable.
The main problem with the Baum-Welch algorithm is that there may
exist several local maxima of the target function and it is not
guaranteed that we reach the global maximum: the convergence may
lead to a local maximum. A useful way to circumvent this pitfall
is to run the algorithm several times, each time with different
initial values for .
If we reach the same maximum most of
the times, it is highly probable that this is indeed the global
maximum.
Next: Profile Alignment
Up: Hidden Markov Models
Previous: Forward and Backward Probabilities
Itshack Pe`er
1999-01-24