As always, we assume that the characters are pairwise independent, and that the
branching is a Markov process, that is, the probability of a node having a given
label is a function only of the state of the parent node and the branch length,
t, between them. Our model also includes a distance function to compute the
latter probability, i.e.:
![]() ,
the probability that
state x will transform into state y within the time tvu. We further assume
that the character frequencies are fixed throughout the evolutionary history, and
that they are given as P(x).
,
the probability that
state x will transform into state y within the time tvu. We further assume
that the character frequencies are fixed throughout the evolutionary history, and
that they are given as P(x).

First, let us deal with a simple case, where there is only one character
identifying each species. Since the labels of the internal nodes are unknown, we
need to sum over all possible reconstructions. For example, for the tree
illustrated in figure 8.11, we can immediately write down the
following formula:
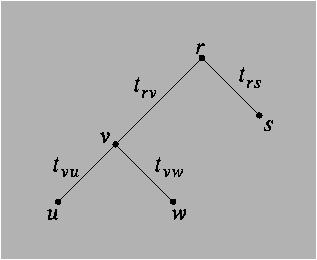 |
To expand the formula for multiple characters, we simply need to repeat the above calculation for each character separately, and then multiply the results (recall the assumption that the characters are pairwise independent). The general equation is now:
| L | = | 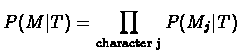 |
|
| = |  |
||
| = | ![$\displaystyle \prod_{\rm {character} \ j} \ \{\ \sum_{\rm {reconstruction} \ R}...
...
\prod_{\rm {edge} \ u \rightarrow v} P_{u \rightarrow v}(t_{uv})\ \right] \ \}$](img79.gif) |
(10) |
Note: The trees inferred by maximum likelihood appear from this
description to be rooted trees. However, if the model of character substitution is
reversible, i.e.,
![]() ,
then the tree
is actually unrooted - the root can be chosen arbitrarily, without any change is the likelihood of the tree.
,
then the tree
is actually unrooted - the root can be chosen arbitrarily, without any change is the likelihood of the tree.
It now remains to show how this calculation can be performed efficiently. The
following dynamic-programming ``pruning'' algorithm was introduced by Felsenstein
[3].
We can take this approach because of
the tree likelihood properties in the Markov's model:
Additivity -
![]()
Reversibility-
![]()
Calculating the likelihood of a tree using Dynamic Programming:
For a character j, denote:
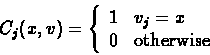 |
(11) |
![\begin{displaymath}C_j(x,v) = \left[ \ \sum_y C_j(y,u) \cdot P_{x \rightarrow y}...
...[ \ \sum_y C_j(y,w) \cdot P_{x \rightarrow y}(t_{vw})\ \right]
\end{displaymath}](img84.gif) |
(12) |
![\begin{displaymath}L = \prod_{j=1}^{m} \ \left[ \ \sum_x C_j(x,root) \cdot P(x)\ \right]
\end{displaymath}](img85.gif) |
(13) |
Complexity: For n species, m characters, and k possible
states for each character, we perform
![]() work in O(n) nodes, so
the running time of the algorithm is
work in O(n) nodes, so
the running time of the algorithm is
![]() .
.
