Learning and Evolution: The Baldwin Effect
(Lecture given by Yael Niv, April 1998)
Evolution, as a global-level process, whose substrates are whole species, does not deal with the level of the individual. Learned traits, however, benefit only the level of the individual, as they are not transferred from the phenotype to the genotype, and thus can not effect the next generation of the species. Combine the above, and you are faced with an interesting question: why has evolution so consistently selected creatures capable of learning?
One answer is immediate: the ability to learn allows creatures to cope with a changing environment, thus benefiting the population by guarding it from sudden extinction due to such changes. The Baldwin Effect, first proposed by J. Baldwin and L. Morgan in 1896, poses a different kind of answer to the question. According to the Baldwin Effect, “Learned behavior and characteristics at the level of individuals, can significantly effect evolution at the level of the species” (French and Messinger, 1996). The idea proposed here, is that although there is no direct transfer of information from the phenotypic level to that of the genotype, individually learned behavior can directly effect Darwinian evolution at the genotypic level, by guiding the evolutionary search.
The interaction between evolution and learning is bi-directional: learning changes the fitness of individuals in the population, thus relocating them in the evolutionary search space. As a result, evolution will also (but not only) select for good learners. Hinton and Nowlan (1987) claim further, that learning actually alters the shape of the search space in which evolution operates, and thereby provides good evolutionary paths toward sets of co-adapted alleles. This is demonstrated by the following combinatorial example.
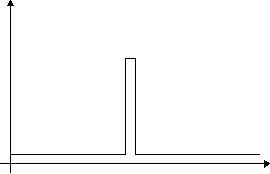
Lets take a neural network consisting of 20 connections, each of which can either exist or be absent. Now imagine a hypothetical extreme case, in which only one choice of the possible connections results in higher fitness. The fitness landscape in this case, looks like the one depicted in figure 1. This landscape poses a serious problem for an evolutionary search, which is really like a search for a needle in a haystack. There are no "paths" leading to the optimal genotype, and unless we have reached the optimal solution, there is no indication as to how close we are to it. The search here is so difficult, because this is a problem calling for co-adaptation of alleles - the correct adaptation of one allele (one connection), does not result in higher fitness, but only the correct adaptation of all the alleles is rewarded. When we are still far from the solution ("far" meaning more than one mutation away from the optimal solution), the mutation of a "wrong" allele to a "correct" one, is not favored over a mutation of a "correct" allele to a "wrong" one. Even worse, once we have reached the optimal genotype, mating with a partner who doesn't have the exact same genotype will result in an unfit offspring. In this case the correct genotype simply can't proliferate.
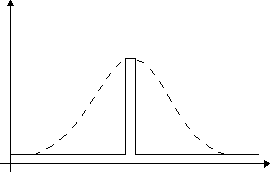
The situation improves dramatically, if the genotype defines only a portion of the network connections, and the rest are learned throughout lifetime. The search space is now altered so that there is a zone of increased fitness around the optimal genotype (see figure 2): The fitness score is actually given to the phenotype (the selection is performed on "adult" networks), so that if an individual with a certain genotype has better chances of learning the right phenotype, on average that certain genotype receives a higher fitness score. The result is a smoothening of the fitness landscape, which helps guide the evolutionary search, thus making it more effective. Now the search is like looking for a needle in a haystack, with someone telling you when you are close…
In a simulation of the above example, Hinton and Nowlan (1987) use 20 possible connections, directly coded in a genotype using "1" for an existing connection, "0" for the absence of a connection, and "?" for a learned connection. Half of the connections are initially "?". The reproduction is sexual, with recombination. Learning takes place using an oversimplified trial-and-error process, in which in each learning step a random combination is tried for all the "?". There are 1000 (~210) learning steps in a lifetime, and learning stops once the goal combination has been reached. There are 1000 nets per generation, and the chances of reproduction are inversely proportional to (1+19n)/1000 where "n" is the number of learning steps needed to reach the solution. Note that in this simulation, Hinton and Nowlan make a problematic assumption that the genotypic distance (measured by number of mutations) and the distance in the phenotypic space (measured by learning difficulty) are correlated.
The optimal evolutionary search strategy seems to be a genetic search, which collects information about distant regions of the search space (via sexual reproduction), combined with a local hill-climbing search, which utilizes learning processes. According to this, the Baldwin Effect appears to be effective only in fitness landscapes of a certain kind, and the question can be asked - does the real evolutionary landscape fit this criterion? Unfortunately, we don't know the shape of the real fitness landscape without adaptation - the above example seems very extreme, but we must keep in mind, that although the evolutionary real search space seems smoother, this is because we view it through the filter of an adaptive population, through learning organisms. It may well be possible that without adaptation, the picture would be altered dramatically.
French and Messinger (1996) confirm Hinton and Nowlan's (1986) results, and empirically examine the Baldwin Effect further, using a more realistic simulation. The population now consists of agents which have varying metabolic, feeding, locomotive and reproductive characteristics, evolving in a world in which the amount and distribution of food is varied over time. In contrast to the previous simulation, here there is no explicit fitness function, and fitness of an individual is measured by the survival capabilities of the agent. The fitness of a genotype is determined implicitly by how well it survives in the population over time.
In a world in which energy (food) "taxes" are levied for movement, reproduction and existence, a “Good Gene” (GG) is one that results in a “Good Phene” (GP) - a fitness enhancing trait implemented as a reduction of taxes on either locomotion, metabolism, or reproduction. GPs can be learned or inherited (by merit of a GG), and again the assumption is made, that the closer an agent is to the GG, the easier it is for it to learn the GP. Under these conditions, there are two factors that determine the extent to which the GG will proliferate in the population:
Each “Good Phene” has a native plasticity, which determines whether it is a difficult trait to learn, or an easy one. Real life examples for such traits are, for instance, winking (very easy to learn) and humming Middle C (difficult to learn, although some people can do it without learning, as they probably possess the “Good Gene” necessary for this task). The benefit that the GP confers on the agent is important, since too low a benefit will result in a lack of evolutionary pressure towards the GG, and too high a benefit will result in the GG eventually dominating the whole population.
As the simulations show, the real evolutionary value of the Baldwin Effect, is that it gives good (but not too good) genes, a better chance of remaining in the population. Most good genes are of this kind - they confer only a slight selective advantage, which makes them susceptible to random elimination. The Baldwin Effect raises the chances of thegenes to survive in the population, by increasing the number of individuals who effectivelybenefit from the “Good Gene” by acquiring the “Good Phene”, so that close genetic configurations are also preserved.
In conclusion, the above simulations show that the Baldwin Effect can effectively change and smoothen the evolutionary search landscape, aiding mainly the proliferation of moderately good genes.
A Detour: Commentary by Harvey to Nolfi et al. (paper from previous lecture)
Nolfi et al. (1994) demonstrate the advantage that evolution derives from learning, in a simulation in which the learning task differs from the evolutionary task. Compared to evolution without learning, it is shown, that the mean fitness of the population is improved, even by learning a task that does not contribute directly to survival. After a number of generations, neural networks that have learned the learning task (prediction of outcome of the agent's actions) better, perform better on the survival task (finding food).
These results are interpreted by the authors, in terms of a dynamic correlation between the evolutionary fitness surface, and the learning surface. In a learning population, evolution selects for individuals placed in areas of dynamic correlation between the two surfaces, so that uphill movement in one plane will result in an improvement in the other as well.
Harvey (1996) rejects this interpretation, and points out a number of flaws in the simulations used: Nolfi et al. used a-sexual reproduction, and implemented evolutionary selection by allowing the best 20 agents (out of 100) to each reproduce 5 times. Under these conditions, the selection pressure is very large (a successful agent has 500% more offsprings then average), resulting in premature convergence - an elite will take over the whole population in as few as 5 generations, and the population will eventually consist of one main genotype (the “elite”), surrounded by close mutations.
When learning is added, the elite is not improved, but the mean performance is improved due to relearning of the optimal weights, by agents that had drifted away from the elite by means of mutations. Furthermore, the improvement due to an apparently unrelated learning task, is not so surprising: When good performance on a certain task is degraded by random mutations, it can be shown that training on any unrelated second task will improve performance on the original task, at least initially.
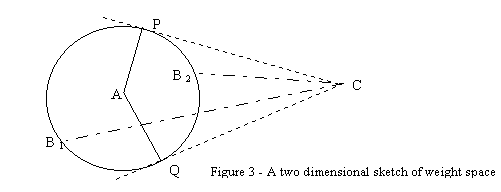
Consider figure 3, which represents the weight space of a network with only two dimensions. "A" represents the weights of a network trained on task A (for example, these are the weights of the elite in terms of the survival task). "B1" and "B2" are sets of weights perturbed from A through mutations. "C" is the optimal weights for performing a different task, C. As can be seen, the trajectories from B1 and B2 to C (representing movement in weight space due to training on task C) initially pass through weight configurations that are, in some cases, closer to A (in the case of B1 performance on task A initially improves, while in the case of B2 it doesn't). In fact, any mutated position falling on the larger arc PQ should improve performance. Thus, the majority of the perturbed cases would improve on task A due to the unrelated second task. If C were to fall inside the circle (tasks A and C are somewhat related), this majority would then be 100% of the perturbed cases. Also, note that the higher the weight space dimension, the larger the large arc PQ becomes, relative to the small arc PQ.
References
[1] French, R.M. and Messinger, A., 1996. Genes, Phenes and the Baldwin Effect: Learning and Evolution in a simulated population. Alife 5 (conference volume), 277-282.
[2] Harvey, I., 1996. Relearning and Evolution in Neural Networks. Adaptive Behavior 4(1), 81-84.
[3] Hinton, G.E. and Nowlan, S.J., 1986. How learning can guide evolution. Complex Systems 1, 495-502.
[4] Nolfi, S., Elman, J.L. and Parisi, D., 1994. Learning and Evolution in Neural Networks. Adaptive Behavior 3(1), 5-28.