


Next: References
Up: No Title
Previous: Multiple Alignment with Profile
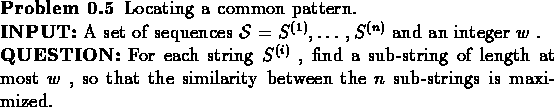
Let
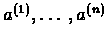 be the starting indices of the chosen
sub-strings in
be the starting indices of the chosen
sub-strings in
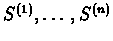 ,
respectively. We
introduce the following notations:
,
respectively. We
introduce the following notations:
We therefore wish to maximize the logarithmic likelihood score:
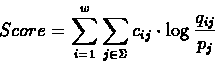 |
(70) |
To accomplish this task, we perform the following iterative
procedure:
- 1.
- Initialization: Randomly choose
.
- 2.
- Randomly choose
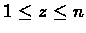 and calculate the cij,
qij and pj values for the strings in
and calculate the cij,
qij and pj values for the strings in
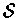
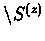 .
.
- 3.
- Find the best substring of S(z) according to the model,
and determine the new value of a(z). This is done by
applying the algorithm for local alignment for S(z) against the profile of the current pattern.
- 4.
- Repeat steps 2 and 3 until the improvement of the score is less then
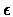 .
.
Unlike the profile HMM technique, the Gibbs sampling algorithm
(due to Lawrence et al. [8]) does not rely on
any substantial theoretic basis. However, this method is known to
work in specific cases.
Known problems:
- Phase shift - The algorithm may converge on an
offset of the best pattern.
- The value of w is usually unknown. Choosing different
values for w may significantly change the results.
- The strings may contain more than a single common
pattern.
- As is the case with the Baum-Welch algorithm, the
process may converge to a local maximum.
Next: References
Up: No Title
Previous: Multiple Alignment with Profile
Peer Itsik
2000-12-19