Face Recognition from Blurred Images
(With Inna Stainvas, Amiram Moshaiov)
This project involves the study of different learning goals for artificial
neural networks and their effects on performance in recognition of
low-quality - blurred, partially occluded and lossy compressed face images.
These learning rules may be represented by different information
theoretic constraints, such as BCM, ICA, EM etc. We show however that
a more mathematically simple reconstruction constraints achieve
improved performance on original and corrupted inputs.
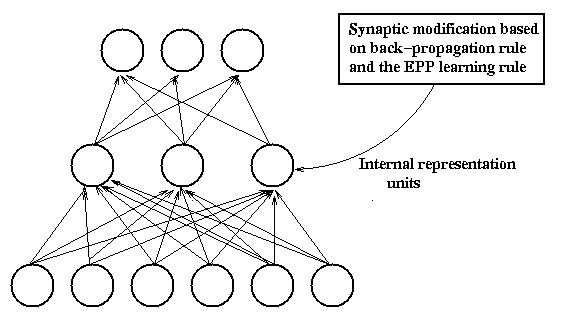
Combined classification/reconstruction network architecture

This architecture attempts to reconstruct the images and to
classify them from the same low-dimensional (hidden)
representation. Like the hybrid architecture presented above, it
attempts to find more features than those that are needed for
classification from a small set of training patterns and is thus more
robust to image degradation. This specific architecture turns out to
be superior to classical feed-forward architectures as well as to
hybrid architectures with various information-theoretic motivated
unsupervised feature extraction.
The combined learning rule for the hidden layer units is a composition
of the error back-propagation from the reconstruction layer and the
recognition layer. The relative influence of each of the output
layers is determined by a constant $\lambda$ which is supposed to
represent the tradeoff between reconstruction and classification ability.
Some examples of the normalized "clean" TAU data base

Training is done either on clean or corrupted data, while the
network is constrained to reconstruct the clean data (so as to
generate features that are insensitive to blur or other image
degradation).
Images after Gaussian Blur and mean intensity removal

Due to the compression via the small hidden layer, reconstructed images
are not exact copies of the input.
Reconstructed faces are robust to different types of occlusion.
Below we show reconstructed faces for Difference of Gaussians
DOG blurred images. The DOG filter is a bandpass filter that is supposed to enhance edges.
Reconstruction by the hybrid NN
 The first image is a clean "caricature" face (mean removed).
The next is the DOG filtered image,
the next two faces are reconstruction of NN with lambda=0, lambda=0.25,
the last face is reconstruction of ensemble of NNs, i.e. the average of
reconstructed images of all NNs with different lambda parameters.
(Lambda is the constant that determines the ratio between the classification
task and the recognition task.)
The first image is a clean "caricature" face (mean removed).
The next is the DOG filtered image,
the next two faces are reconstruction of NN with lambda=0, lambda=0.25,
the last face is reconstruction of ensemble of NNs, i.e. the average of
reconstructed images of all NNs with different lambda parameters.
(Lambda is the constant that determines the ratio between the classification
task and the recognition task.)
Types of Image Degradation Used

From left to right:
Difference of Gaussians DOG blur (band pass filter);
Gaussian blur (low pass filter);
Motion blur (in the diagonal direction) (low pass filter);
High-pass filtered image;
Salt and Pepper noise;
Gaussian noise;
Image restoration
Denoising and deblurring may be done before classification of the
corrupted images, However, it is well-known that image restoration is
an ill-posed problem which may be unstable, i.e., the solution may be
very sensitive to small perturbations.
We have been testing the following image restoration methods:
 From left to right: clean image, Gaussian blurred image with std=2
and additive Gaussian noise,
blind deconvolution, deconvolution with known blurring
filter.
From left to right: clean image, Gaussian blurred image with std=2
and additive Gaussian noise,
blind deconvolution, deconvolution with known blurring
filter.
Cursive Word Recognition
(With Tal Steinhertz, Ehud Rivlin)
We are currently working on a
development of a set of preprocessing algorithms that can
be used with
any off-line handwritten word recognition system.
Each algorithm can be adapted to be used separately or as part of a
complete preprocessing system.
Following is a list of the algorithms developed:
Currently under development:
Following is a short demonstration of some of the preprocessing
developed. The first image represents a scanned cursive word image
(beautiful) after going through binarization.
Original image (left) and Correcting for lost loops (right)

 As a first stage one should look for lost loops. Indeed, two lost
loops were found as can be seen in the next image: a hidden loop that
belongs to the 'a' character and a smaller one in the middle of the
'f'. As a by-product of this process we have also obtained a correct
stroke wide estimation that can be used for further processing.
As a first stage one should look for lost loops. Indeed, two lost
loops were found as can be seen in the next image: a hidden loop that
belongs to the 'a' character and a smaller one in the middle of the
'f'. As a by-product of this process we have also obtained a correct
stroke wide estimation that can be used for further processing.
The next left image presents the pseudo-skeleton of the word image. We use
the term pseudo since we do not produce a skeleton that satisfies the
mathematical definition of an object skeleton. However we have
fulfilled our goals of preserving all meaningful strokes with their
original properties such as direction, curvature if exists, length
etc. Unfortunately we still have some noise and artifacts, and we are
currently working on their reduction together with smoothing the edges
of the resulting skeleton.
The respective skeleton of the word image (left) and Slant
correction (right)


The right image shows the previously extracted skelton after going
through the important preprocessing of slant correction. Note that all
ascenders and descenders that leaned in all previous images became
erect. The slant angle is found through the skeleton, but can be used
to correct the original image as well and therefore it is very
powerful also as a stand alone algorithm.