


Next: The Learning Algorithms
Up: Reinforcement Learning - Final
Previous: Notations
The Parallel Sampling Model
The
 is a model of an ideal
exploration policy, in the sense that every state-action pair is
sampled with the same frequency. We define a subroutine called
PS(M) that simulates the Parallel Sampling Model as follows: a
single call to PS(M) returns, for every
state-action pair (s,a), a random next state s' distributed
according to the transition distribution
Pasj. Thus a
single call to PS(M) is simulating
is a model of an ideal
exploration policy, in the sense that every state-action pair is
sampled with the same frequency. We define a subroutine called
PS(M) that simulates the Parallel Sampling Model as follows: a
single call to PS(M) returns, for every
state-action pair (s,a), a random next state s' distributed
according to the transition distribution
Pasj. Thus a
single call to PS(M) is simulating
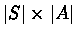 transitions
in the given MDP, and returns
next states.
transitions
in the given MDP, and returns
next states.
Of
course often this model is only an ideal and not an applicable
procedure; the advantage of using such a model of perfect sampling
method is that it enables us to separate the analysis of the
learning algorithms from the quality of the policy we can
sample. Using the analysis for the ideal exploration policy we can
also bound the learning rate of any given exploration policy that
visits every state-action pair infinitely often, by approximating
the procedure PS(M) with taking enough samples of the
exploration function, such that with good probability every
state-action pair is visited.
Yishay Mansour
2000-05-30