


Next: Q-learning and SARSA algorithms
Up: Policy Sampling
Previous: Problem of sampling
conclusion:
- 1.
- To calculate the ratio we don't need any knowledge on the Model
only about the two policies we use.
- 2.
- The ratio is
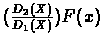 is the case of Importance Sampling.
is the case of Importance Sampling.
- 3.
- 1+2 imply we can use samples from one policy to calculate samples on another policy.
- 4.
- conclusion 3 explain why Q-learning can work.
- 5.
- The Variance must be limited to avoid errors.
Yishay Mansour
2000-01-07