


Next: Forward Updates Versus Backward
Up: TD( ) algorithm
Previous: TD( ) algorithm
TD(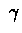 ) as generalization of MC and TD(0)
methods
) as generalization of MC and TD(0)
methods
MC uses overall return of the run to perform update, i.e.,
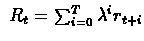
TD(0) uses only
immediate reward to make update and its update has the form,
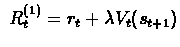
We can think about other options between those two extremes. For
example we can use two immediate reward values , i.e. ,
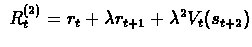
Generally - if n values are in use, we have,
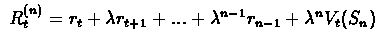
Note: If 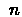 is more than
number of steps to the end of the run, we set all the rewards
after the run end to 0.
is more than
number of steps to the end of the run, we set all the rewards
after the run end to 0.
The update is defined as
![$\ \triangle V_{t}(s_{t}) =
\alpha[R_{t}^{(n)}-V_{t}(s_{t})] $](img54.gif)
Update can be performed:
- 1.
- online:
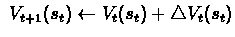
- 2.
- off-line:
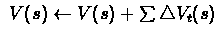
It is easy to see that operator
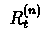 is
is
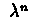 contracting.
contracting.
![$\ [ \Vert R_{t}^{(n)}(V^{(1)}) -
R_{t}^{(n)}(V^{(2)})\Vert = \lambda^{n}\Vert V^{(1)} - V^{(2)}\Vert ] $](img59.gif)
So we expect to get improvement and reduce error while making
iterations.
The central remaining question is choice of
. One way to
do it is to use weighed average of all possible values.
The method
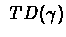 gives a geometric distribution with
parameter
over
,
gives a geometric distribution with
parameter
over
,
i.e. weight of
is
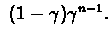
We define
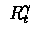 to be
to be
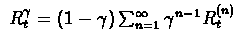
For
finite run this expression can be rewritten as :
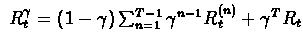
- 1.
- If
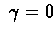 then weight of
then weight of
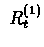 is 1 and weights
of any other
equals 0. This reduces TD(0), which
we introduced before.
is 1 and weights
of any other
equals 0. This reduces TD(0), which
we introduced before.
- 2.
- For
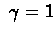 we'll get
we'll get
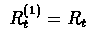 (total reward) .
(total reward) .
Next: Forward Updates Versus Backward
Up: TD( ) algorithm
Previous: TD( ) algorithm
Yishay Mansour
2000-01-06