


Next: First Visit
Up: Evaluating Policy Reward
Previous: Evaluating Policy Reward
The Naive Approach
for each 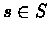 :
:
Run  from s for m times, where the i-th run is Ti.
from s for m times, where the i-th run is Ti.
Let ri be the reward of Ti.
Estimate the reward of policy starting from s, by :
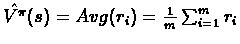
The variables ri are independent since the runs Ti are independent. By Chernoff's theorem :
![$Prob[\vert\hat{V^{\pi}(s)}-V^{\pi}(s)\vert\geq \gamma]\leq 2e^{-2m\gamma^{2}}$](img94.gif)
This implies that :
![$Prob[\exists s \in S : \vert\hat{V^{\pi}(s)}-V^{\pi}(s)\vert \geq \gamma] \leq ...
...}-V^{\pi}(s)\vert \geq \gamma] \leq \vert S\vert 2e^{-2m\gamma^{2}} = \epsilon $](img95.gif) .
.
for
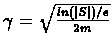 the above holds.
the above holds.
Yishay Mansour
1999-12-16