


Next: The Naive Approach
Up: No Title
Previous: Evaluating the average
Evaluating Policy Reward
Let  be a policy.
We would like to calculate the reward of policy :
be a policy.
We would like to calculate the reward of policy :
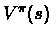 .
.
For simplicity, we assume that there exist a state s0 in the MDP, such that s0 has a reward of 0, and
Prob(s0|s0,a) = 1 :
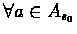 .
.
Also, we assume that each policy reachs state s0 within a finite number of steps with probability 1.
Under these assumptions, we can assume each run is finite.
Yishay Mansour
1999-12-16