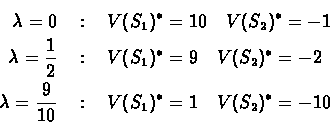Next: About this document ...
Up: Computing the Optimal Policy
Previous: Uniqueness of
Example:
Using the same example we calculate the
optimal return value to be:
Thus
If we examine different values of 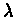 we get different
optimal actions in S1.
we get different
optimal actions in S1.
For example:
Note that as increases the optimal policy at S1
changes from a12 to a11.
Yishay Mansour
1999-11-24
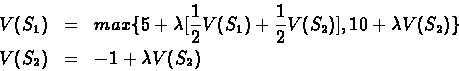
![\begin{eqnarray*}V(S_{2}) & = & -\frac{1}{1 - \lambda}\\ V(S_{1})& = & max\{5 +
...
...}\frac{1}{1 - \lambda}],\
10 - \lambda \frac{1}{1 - \lambda}\}
\end{eqnarray*}](img119.gif)