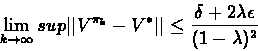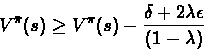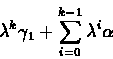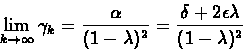In this section will make two assumptions on our approximation.
(Both of them are rather strong.)
Assume the algorithm outputs
such that
1.
2.
For some positive scalars
and .
Theorem 11.2
The sequence of policies
generated by the approximate policy iteration algorithm satisfies
Proof:We will first show that a policy generated by the policy update can not be much worse than the current policy.
We will prove it by using the following lemmas
Lemma 11.3
Let
be some policy and V is a value function satisfies
for some
.
Let
be a policy that satisfies:
for some
then
Proof:Let
and
so
Hence we will have
Therefore we derive,
1.
>From the hypothesis of the lemma we have,
2.
Using inequality 1, we obtain
Using inequality 2, we obtain
Thus we conclude the following:
and the desired result follows.
be
We apply the lemma above with
and
As a result we have
We now let
to be distance from the optimum.
Lemma 11.4
Proof:By the definition of :
we then have
(assumption 1)
(assumption 2)
(assumption 1)
(definition of )
Thus
(fixed pint of the operator)
(definition of )
(using the previous)
This implies that,
will use the former lemma and the
definition to prove the theorem
Since one can easily see from the equation
that bounding is not dependent on k. Therefore, we can define the following
while
is constant, which is not dependent on K. Then we have
By opening the recursion we will get
By taking the limit superior of the equation as
to obtain