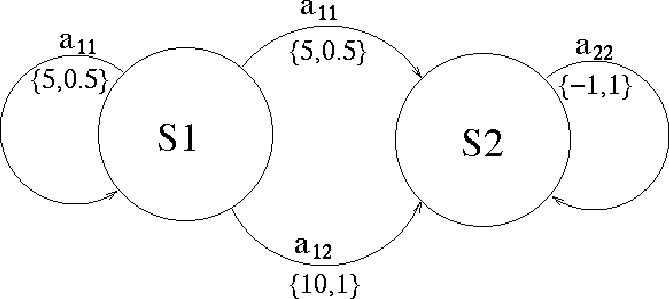
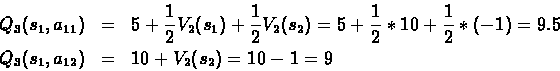Lets define a state machine with two states s1, s2.
Formally, in the example we have:
time:
![]()
states:
![]()
actions:
![]()
reward: rt(s1,a11) = 5, rt(s1,a12) = 10, rt(s2,a21) = -1
final reward: rN(s1) = 0, rN(s2) = 0
transition function: Pt(s1|s1,a11) = 0.5, Pt(s2|s1,a11) = 0.5
Pt(s2|s1,a12) = 1, Pt(s2|s2,s21) = 1
Now we want to maximize the return. First we compare two deterministic policies:
![]() - always chooses a11 when in state s1.
- always chooses a11 when in state s1.
![]() - always chooses a12 when in state s2.
- always chooses a12 when in state s2.
Recall that ![]() is the expected return of policy
is the expected return of policy ![]() in N time steps.
in N time steps.
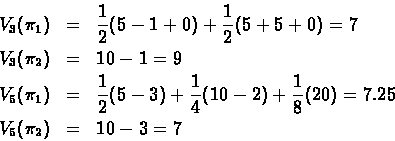
Lets try determining the best policy. We do this by looking first at the reward gained in the last step, for N=2:
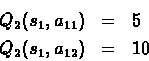
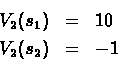
For N=3, we use the optimal policy for N=2, after we do one action.